
Original source: https://jalammar.github.io/illustrated-transformer/

Jay Alamar
Visualitzar l’aprenentatge automàtic un concepte alhora.
@JayAlammar a Twitter. Canal de YouTube
Debats: Hacker News (65 punts, 4 comentaris) , Reddit r/MachineLearning (29 punts, 3 comentaris)
Watch: MIT’s Deep Learning State of the Art conferència que fa referència a aquesta publicació
Presentada en cursos a Stanford , Harvard , MIT , Princeton , CMU i altres
A la publicació anterior, vam analitzar l’atenció , un mètode omnipresent en els models moderns d’aprenentatge profund. L’atenció és un concepte que va ajudar a millorar el rendiment de les aplicacions de traducció automàtica neuronal. En aquesta publicació, veurem The Transformer , un model que utilitza l’atenció per augmentar la velocitat amb què es poden entrenar aquests models. El Transformer supera el model de traducció automàtica neuronal de Google en tasques específiques. El major benefici, però, prové de com The Transformer es presta a la paral·lelització. De fet, la recomanació de Google Cloud és utilitzar The Transformer com a model de referència per utilitzar la seva oferta de Cloud TPU . Per tant, intentem separar el model i veure com funciona.
El transformador es va proposar al paper Atenció és tot el que necessiteu . Una implementació de TensorFlow està disponible com a part del paquet Tensor2Tensor . El grup de PNL de Harvard va crear una guia que anotava el document amb la implementació de PyTorch . En aquesta publicació, intentarem simplificar una mica les coses i introduir els conceptes un per un per tal que sigui més fàcil d’entendre a les persones sense un coneixement profund de la matèria.
Actualització del 2020 : he creat un vídeo de “Transformador narrat” que és un enfocament més suau del tema:
Una mirada d’alt nivell
Comencem mirant el model com una única caixa negra. En una aplicació de traducció automàtica, prendria una frase en un idioma i la traducció en un altre.
Obrint aquesta bondat Optimus Prime, veiem un component de codificació, un component de descodificació i connexions entre ells.
El component de codificació és una pila de codificadors (el paper n’apila sis uns sobre els altres; no hi ha res de màgic sobre el número sis, definitivament es pot experimentar amb altres arranjaments). El component de descodificació és una pila de descodificadors del mateix nombre.
Els codificadors són tots idèntics en estructura (tot i que no comparteixen pesos). Cadascun es divideix en dues subcapes:
Les entrades del codificador flueixen primer a través d’una capa d’autoatenció, una capa que ajuda el codificador a mirar altres paraules a la frase d’entrada mentre codifica una paraula específica. Mirarem més de prop l’autoatenció més endavant a la publicació.
Les sortides de la capa d’autoatenció s’alimenten a una xarxa neuronal de feed-forward. La mateixa xarxa de feed-forward s’aplica de manera independent a cada posició.
El descodificador té aquestes dues capes, però entre elles hi ha una capa d’atenció que ajuda el descodificador a centrar-se en les parts rellevants de la frase d’entrada (com el que fa l’atenció als models seq2seq ).
Introduir els tensors a la imatge
Ara que hem vist els components principals del model, comencem a veure els diferents vectors/tensors i com flueixen entre aquests components per convertir l’entrada d’un model entrenat en una sortida.
Com és el cas de les aplicacions PNL en general, comencem convertint cada paraula d’entrada en un vector mitjançant un algorisme d’incrustació .

Cada paraula està incrustada en un vector de mida 512. Representarem aquests vectors amb aquests quadres senzills.
La incrustació només es produeix al codificador més baix. L’abstracció que és comuna a tots els codificadors és que reben una llista de vectors cadascun de la mida 512: al codificador inferior seria la paraula incrustacions, però en altres codificadors, seria la sortida del codificador que es troba directament a sota. . La mida d’aquesta llista és un hiperparàmetre que podem establir; bàsicament, seria la longitud de la frase més llarga del nostre conjunt de dades d’entrenament.
Després d’incrustar les paraules a la nostra seqüència d’entrada, cadascuna d’elles flueix per cadascuna de les dues capes del codificador.
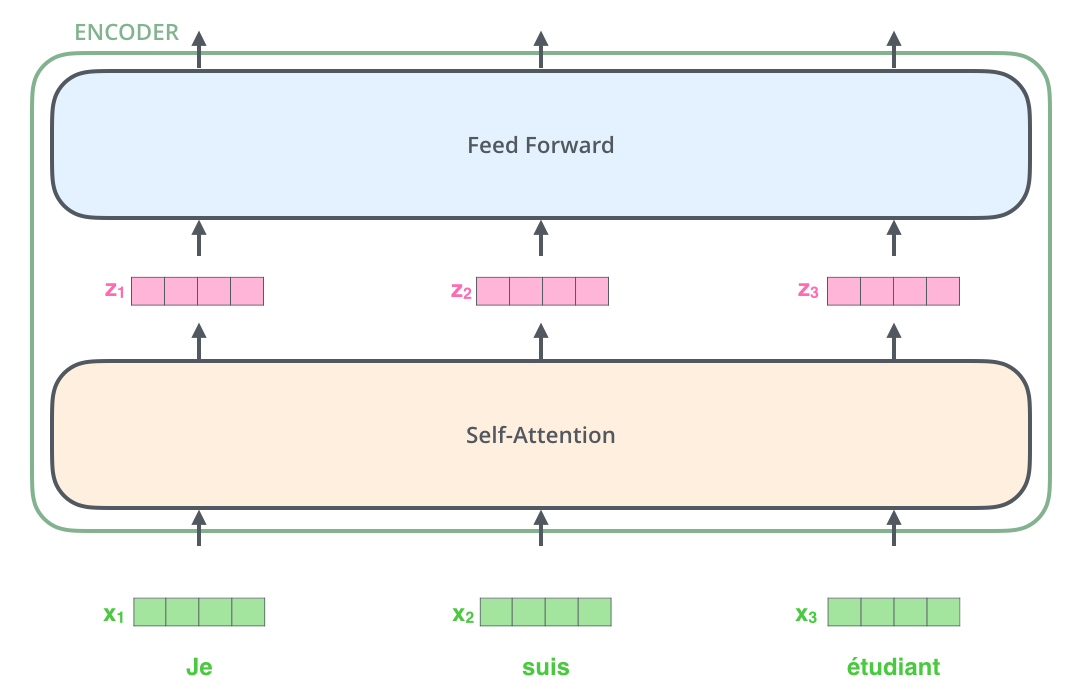
Aquí comencem a veure una propietat clau del transformador, que és que la paraula en cada posició flueix pel seu propi camí al codificador. Hi ha dependències entre aquests camins a la capa d’autoatenció. Tanmateix, la capa d’alimentació anticipada no té aquestes dependències i, per tant, els diferents camins es poden executar en paral·lel mentre flueixen per la capa d’alimentació anticipada.
A continuació, canviarem l’exemple a una frase més curta i veurem què passa a cada subcapa del codificador.
Ara estem codificant!
Com ja hem esmentat, un codificador rep una llista de vectors com a entrada. Processa aquesta llista passant aquests vectors a una capa d'”autoatenció”, després a una xarxa neuronal de feed-forward, i després envia la sortida cap amunt al següent codificador.
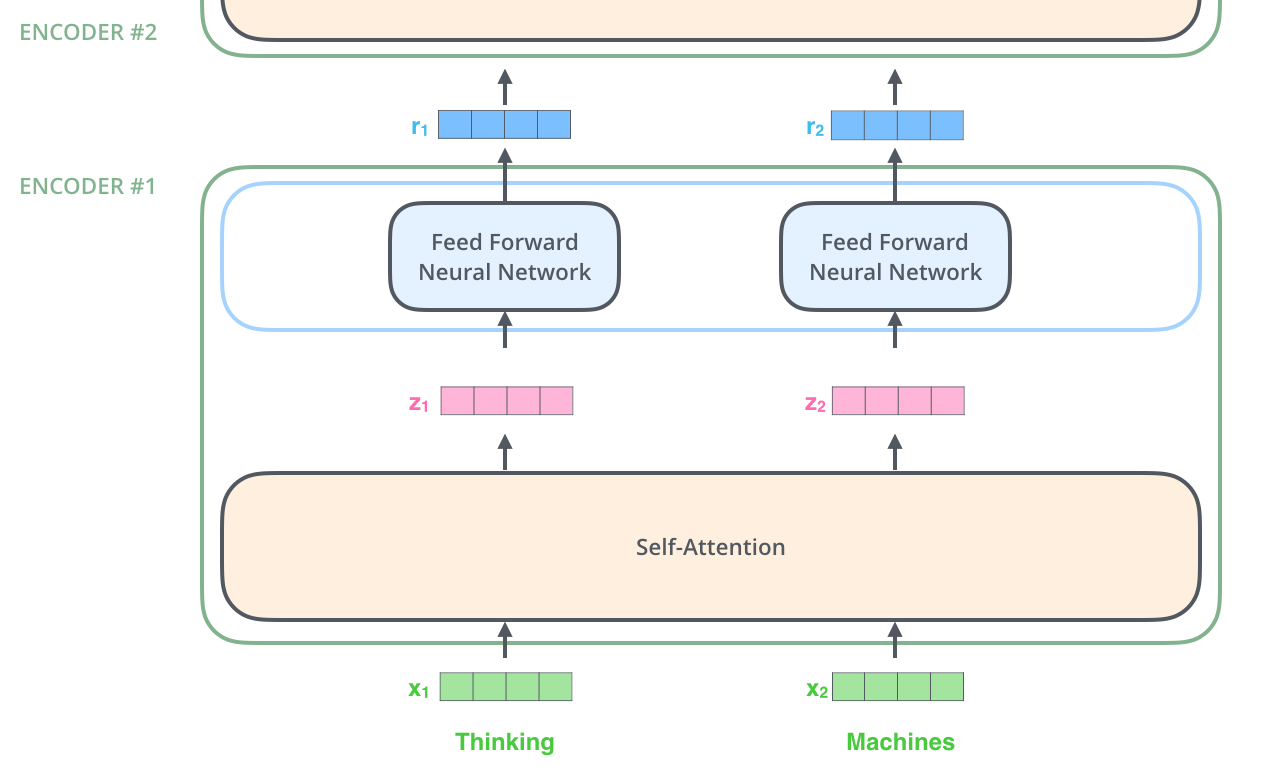
La paraula en cada posició passa per un procés d’autoatenció. Aleshores, cadascú travessa una xarxa neuronal d’alimentació anticipada, exactament la mateixa xarxa amb cada vector que la travessa per separat.
Autoatenció a un alt nivell
No us deixeu enganyar perquè tiri la paraula “autoatenció” com si fos un concepte que tothom hauria de conèixer. Personalment, no m’havia trobat mai amb el concepte fins que vaig llegir el paper L’atenció és tot el que necessites. Anem a destil·lar com funciona.
Diguem que la frase següent és una frase d’entrada que volem traduir:
” The animal didn't cross the street because it was too tired”
A què es refereix “ella” en aquesta frase? Es refereix al carrer o a l’animal? És una pregunta senzilla per a un humà, però no tan simple per a un algorisme.
Quan el model està processant la paraula “ell”, l’autoatenció li permet associar “ell” amb “animal”.
A mesura que el model processa cada paraula (cada posició de la seqüència d’entrada), l’autoatenció li permet mirar altres posicions de la seqüència d’entrada per buscar pistes que puguin ajudar a una millor codificació d’aquesta paraula.
Si esteu familiaritzat amb els RNN, penseu en com mantenir un estat ocult permet que un RNN incorpori la seva representació de paraules/vectors anteriors que ha processat amb l’actual que està processant. L’autoatenció és el mètode que utilitza Transformer per incorporar la “comprensió” d’altres paraules rellevants a la que estem processant actualment.
![]()
A mesura que estem codificant la paraula “it” al codificador #5 (el codificador superior de la pila), part del mecanisme d’atenció es va centrar en “L’animal” i va incorporar una part de la seva representació a la codificació de “it”.
Assegureu-vos de consultar el quadern Tensor2Tensor on podeu carregar un model de Transformer i examinar-lo mitjançant aquesta visualització interactiva.
Autoatenció al detall
Vegem primer com calcular l’autoatenció mitjançant vectors, i després procedim a veure com s’implementa realment, utilitzant matrius.
El primer pas per calcular l’autoatenció és crear tres vectors a partir de cadascun dels vectors d’entrada del codificador (en aquest cas, la incrustació de cada paraula). Així, per a cada paraula, creem un vector de consulta, un vector clau i un vector de valor. Aquests vectors es creen multiplicant la incrustació per tres matrius que hem entrenat durant el procés d’entrenament.
Observeu que aquests nous vectors tenen una dimensió més petita que el vector d’incrustació. La seva dimensionalitat és 64, mentre que els vectors d’entrada/sortida d’incrustació i codificador tenen una dimensionalitat de 512. No HAN de ser més petits, aquesta és una elecció d’arquitectura per fer que el càlcul de l’atenció multicapçal (sobretot) sigui constant.
![]()
Multiplicant
x1 per la matriu de pes
WQ es produeix
q1 , el vector “consulta” associat amb aquesta paraula. Acabem creant una “consulta”, una “clau” i una projecció de “valor” de cada paraula de la frase d’entrada.
Quins són els vectors “consulta”, “clau” i “valor”?
Són abstraccions útils per calcular i pensar en l’atenció. Un cop llegiu com es calcula l’atenció a continuació, sabreu pràcticament tot el que necessiteu saber sobre el paper que juga cadascun d’aquests vectors.
El segon pas per calcular l’autoatenció és calcular una puntuació. Suposem que estem calculant l’autoatenció per a la primera paraula d’aquest exemple, “Pensar”. Hem de puntuar cada paraula de la frase d’entrada amb aquesta paraula. La puntuació determina quant enfocament cal posar en altres parts de la frase d’entrada mentre codifiquem una paraula en una posició determinada.
La puntuació es calcula prenent el producte escalat del vector de consulta amb el vector clau de la paraula respectiva que estem puntuant. Per tant, si estem processant l’autoatenció per a la paraula a la posició #1 , la primera puntuació seria el producte escalat de q1 i k1 . La segona puntuació seria el producte escalat de q1 i k2 .
El tercer i quart pas consisteix a dividir les puntuacions per 8 (l’arrel quadrada de la dimensió dels vectors clau utilitzats al document: 64. Això condueix a tenir gradients més estables. Podrien haver-hi altres valors possibles aquí, però aquest és el per defecte), després passar el resultat mitjançant una operació softmax. Softmax normalitza les puntuacions perquè siguin totes positives i sumin 1.
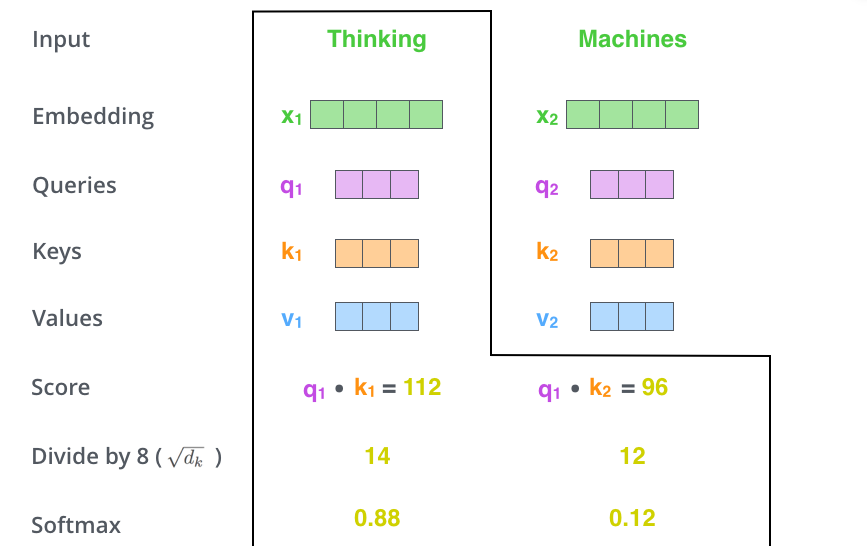
Aquesta puntuació de softmax determina quant s’expressarà cada paraula en aquesta posició. És evident que la paraula en aquesta posició tindrà la puntuació softmax més alta, però de vegades és útil atendre una altra paraula que sigui rellevant per a la paraula actual.
El cinquè pas és multiplicar cada vector de valor per la puntuació softmax (en preparació per resumir-los). La intuïció aquí és mantenir intactes els valors de les paraules en què volem centrar-nos i ofegar les paraules irrellevants (multiplicant-les per nombres minúsculs com 0,001, per exemple).
El sisè pas és sumar els vectors de valors ponderats. Això produeix la sortida de la capa d’autoatenció en aquesta posició (per a la primera paraula).

Això conclou el càlcul d’autoatenció. El vector resultant és el que podem enviar a la xarxa neuronal de feed-forward. En la implementació real, però, aquest càlcul es fa en forma de matriu per a un processament més ràpid. Així que mirem-ho ara que hem vist la intuïció del càlcul a nivell de paraula.
Càlcul matricial de l’autoatenció
El primer pas és calcular les matrius de consulta, clau i valor. Ho fem empaquetant les nostres incrustacions en una matriu X i multiplicant-la per les matrius de pes que hem entrenat ( WQ , WK , WV ).

Cada fila de la matriu
X correspon a una paraula de la frase d’entrada. Tornem a veure la diferència de mida del vector d’incrustació (512, o 4 caixes a la figura) i els vectors q/k/v (64, o 3 caixes a la figura)
Finalment , com que estem tractant amb matrius, podem condensar els passos del dos al sis en una fórmula per calcular les sortides de la capa d’autoatenció.

El càlcul d’autoatenció en forma matricial
La bèstia amb molts caps
El document va perfeccionar encara més la capa d’autoatenció afegint un mecanisme anomenat atenció “de capçals múltiples”. Això millora el rendiment de la capa d’atenció de dues maneres:
- Amplia la capacitat del model per centrar-se en diferents posicions. Sí, a l’exemple anterior, z1 conté una mica de qualsevol altra codificació, però podria estar dominada per la paraula real. Si traduïm una frase com “L’animal no va creuar el carrer perquè estava massa cansat”, seria útil saber a quina paraula es refereix “ella”.
- Dóna a la capa d’atenció múltiples “subespais de representació”. Com veurem a continuació, amb l’atenció multicapçalera no només tenim un, sinó diversos conjunts de matrius de pes de consulta/clau/valor (el transformador utilitza vuit capçals d’atenció, de manera que acabem amb vuit conjunts per a cada codificador/descodificador) . Cadascun d’aquests conjunts s’inicialitza aleatòriament. Després, després de l’entrenament, cada conjunt s’utilitza per projectar les incrustacions d’entrada (o vectors dels codificadors/descodificadors inferiors) en un subespai de representació diferent.
![]()
Amb una atenció multicapçalera, mantenim matrius de pes Q/K/V separades per a cada cap, donant lloc a matrius Q/K/V diferents. Com hem fet abans, multipliquem X per les matrius WQ/WK/WV per produir matrius Q/K/V.
Si fem el mateix càlcul d’autoatenció que hem descrit anteriorment, només vuit vegades diferents amb matrius de pes diferents, acabem amb vuit matrius Z diferents.
Això ens deixa amb una mica de repte. La capa de feed-forward no espera vuit matrius, sinó una única matriu (un vector per a cada paraula). Per tant, necessitem una manera de condensar aquests vuit en una sola matriu.
Com ho fem? Concatem les matrius i les multipliquem per una matriu de pesos addicional WO.
Això és pràcticament tot el que hi ha per a l’autoatenció de diversos caps. És un bon grapat de matrius, m’adono. Permeteu-me intentar posar-los tots en un sol visual perquè els puguem mirar en un sol lloc
Ara que hem tocat els caps d’atenció, revisem el nostre exemple anterior per veure on se centren els diferents caps d’atenció mentre codifiquem la paraula “ella” a la nostra frase d’exemple:
![]()
A mesura que codifiquem la paraula “això”, un cap d’atenció se centra més en “l’animal”, mentre que un altre se centra en “cansat”; en cert sentit, la representació del model de la paraula “ella” s’enfoca en algunes de les representacions. tant d'”animal” com de “cansat”.
Si afegim tota l’atenció a la imatge, però, les coses poden ser més difícils d’interpretar:
Representació de l’ordre de la seqüència mitjançant la codificació posicional
Una cosa que falta al model tal com l’hem descrit fins ara és una manera de tenir en compte l’ordre de les paraules a la seqüència d’entrada.
Per solucionar-ho, el transformador afegeix un vector a cada incrustació d’entrada. Aquests vectors segueixen un patró específic que aprèn el model, que l’ajuda a determinar la posició de cada paraula, o la distància entre les diferents paraules de la seqüència. La intuïció aquí és que afegir aquests valors a les incrustacions proporciona distàncies significatives entre els vectors d’incrustació una vegada que es projecten en vectors Q/K/V i durant l’atenció al producte puntual.
![]()
Per donar al model una idea de l’ordre de les paraules, afegim vectors de codificació posicional, els valors dels quals segueixen un patró específic.
Si suposem que la incrustació té una dimensionalitat de 4, les codificacions posicionals reals serien així:
![]()
Un exemple real de codificació posicional amb una mida d’inserció de joguines de 4
Com podria ser aquest patró?
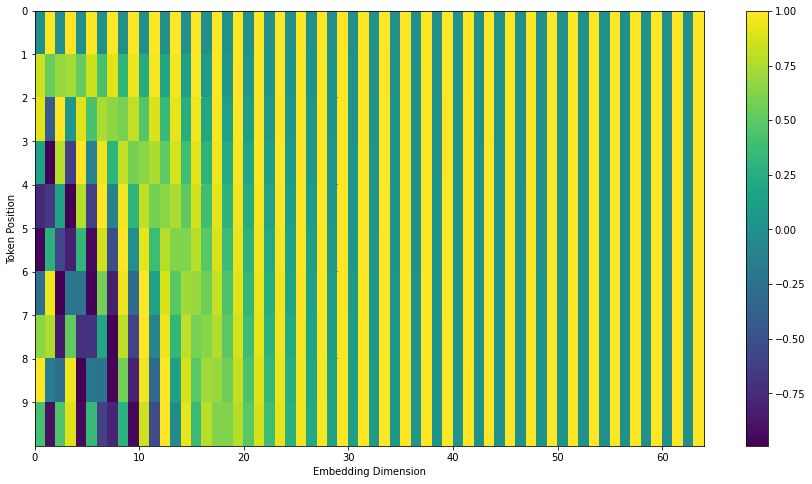
A la figura següent, cada fila correspon a una codificació posicional d’un vector. Així, la primera fila seria el vector que afegiríem a la incrustació de la primera paraula en una seqüència d’entrada. Cada fila conté 512 valors, cadascun amb un valor entre 1 i -1. Els hem codificat per colors perquè el patró sigui visible.
![]()
Un exemple real de codificació posicional per a 20 paraules (files) amb una mida d’inserció de 512 (columnes). Podeu veure que sembla dividit per la meitat pel centre. Això és perquè els valors de la meitat esquerra són generats per una funció (que utilitza el sinus) i la meitat dreta és generada per una altra funció (que utilitza el cosinus). A continuació, es concatenen per formar cadascun dels vectors de codificació posicional.
La fórmula per a la codificació posicional es descriu al document (secció 3.5). Podeu veure el codi per generar codificacions posicionals a get_timing_signal_1d(). Aquest no és l’únic mètode possible per a la codificació posicional. Tanmateix, ofereix l’avantatge de poder escalar longituds de seqüències no vistes (per exemple, si al nostre model entrenat se li demana que tradueixi una frase més llarga que qualsevol de les del nostre conjunt d’entrenament).
Actualització de juliol de 2020: la codificació posicional que es mostra a dalt prové de la implementació de Tensor2Tensor del Transformer. El mètode que es mostra al document és lleugerament diferent, ja que no concatena directament, sinó que entrellaça els dos senyals. La figura següent mostra com és. Aquí teniu el codi per generar-lo :
Els Residus
Un detall de l’arquitectura del codificador que hem d’esmentar abans de continuar, és que cada subcapa (autoatenció, ffnn) de cada codificador té una connexió residual al seu voltant, i va seguida d’un pas de normalització de capa .
Si volem visualitzar els vectors i l’operació de la norma de capa associada a l’atenció personal, semblaria així:
Això també passa amb les subcapes del descodificador. Si pensem en un transformador de 2 codificadors i descodificadors apilats, semblaria així:
El costat del descodificador
Ara que hem cobert la majoria dels conceptes del costat del codificador, bàsicament sabem també com funcionen els components dels descodificadors. Però fem una ullada a com treballen junts.
El codificador comença processant la seqüència d’entrada. A continuació, la sortida del codificador superior es transforma en un conjunt de vectors d’atenció K i V. Aquests han de ser utilitzats per cada descodificador a la seva capa d’atenció al codificador-descodificador, que ajuda el descodificador a centrar-se en els llocs adequats de la seqüència d’entrada:
![]()
Un cop acabada la fase de codificació, comencem la fase de descodificació. Cada pas de la fase de descodificació produeix un element de la seqüència de sortida (la frase de traducció a l’anglès en aquest cas).
Els següents passos repeteixen el procés fins a un especial s’arriba al símbol que indica que el descodificador del transformador ha completat la seva sortida. La sortida de cada pas s’alimenta al descodificador inferior en el següent pas de temps, i els descodificadors fan bombolles els seus resultats de descodificació tal com ho van fer els codificadors. I igual que vam fer amb les entrades del codificador, incrustem i afegim codificació posicional a aquestes entrades del descodificador per indicar la posició de cada paraula.
Les capes d’autoatenció del descodificador funcionen d’una manera lleugerament diferent a la del codificador:
Al descodificador, la capa d’autoatenció només pot atendre les posicions anteriors de la seqüència de sortida. Això es fa emmascarant les posicions futures (establint-les a -inf) abans del pas de softmax en el càlcul d’autoatenció.
La capa “Atenció del codificador-descodificador” funciona igual que l’autoatenció multicapçalera, excepte que crea la seva matriu de consultes a partir de la capa que hi ha a sota i pren la matriu de claus i valors de la sortida de la pila de codificadors.
La capa final lineal i Softmax
La pila del descodificador emet un vector de flotadors. Com ho convertim en una paraula? Aquesta és la feina de la capa lineal final que va seguida d’una capa Softmax.
La capa lineal és una xarxa neuronal senzilla totalment connectada que projecta el vector produït per la pila de descodificadors, en un vector molt més gran anomenat vector logits.
Suposem que el nostre model coneix 10.000 paraules en anglès úniques (el “vocabulari de sortida” del nostre model) que ha après del seu conjunt de dades d’entrenament. Això faria que el vector logits tingués una amplada de 10.000 cel·les, cada cel·la corresponent a la puntuació d’una paraula única. Així és com interpretem la sortida del model seguida de la capa lineal.
Aleshores, la capa softmax converteix aquestes puntuacions en probabilitats (totes positives, totes sumen 1,0). S’escull la cel·la amb la probabilitat més alta i la paraula associada a ella es produeix com a sortida per a aquest pas de temps.
![]()
Aquesta figura comença des de la part inferior amb el vector produït com a sortida de la pila descodificadora. Aleshores es converteix en una paraula de sortida.
Recapitulació de la formació
Ara que hem cobert tot el procés de pas endavant mitjançant un Transformador entrenat, seria útil fer una ullada a la intuïció d’entrenar el model.
Durant l’entrenament, un model no entrenat passaria exactament per la mateixa passada cap endavant. Però com que l’estem entrenant en un conjunt de dades d’entrenament etiquetat, podem comparar la seva sortida amb la sortida correcta real.
Per visualitzar-ho, suposem que el nostre vocabulari de sortida només conté sis paraules (“a”, “am”, “i”, “gràcies”, “estudiant” i “<eos>” (abreviatura de “final de la frase”)). .
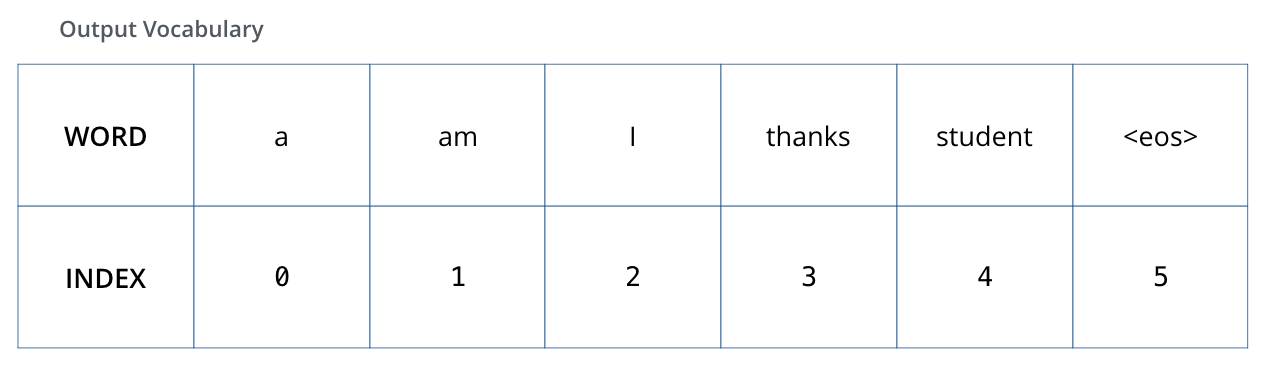
El vocabulari de sortida del nostre model es crea en la fase de preprocessament abans fins i tot de començar l’entrenament.
Un cop definit el nostre vocabulari de sortida, podem utilitzar un vector de la mateixa amplada per indicar cada paraula del nostre vocabulari. Això també es coneix com a codificació one-hot. Així, per exemple, podem indicar la paraula “sóc” amb el següent vector:
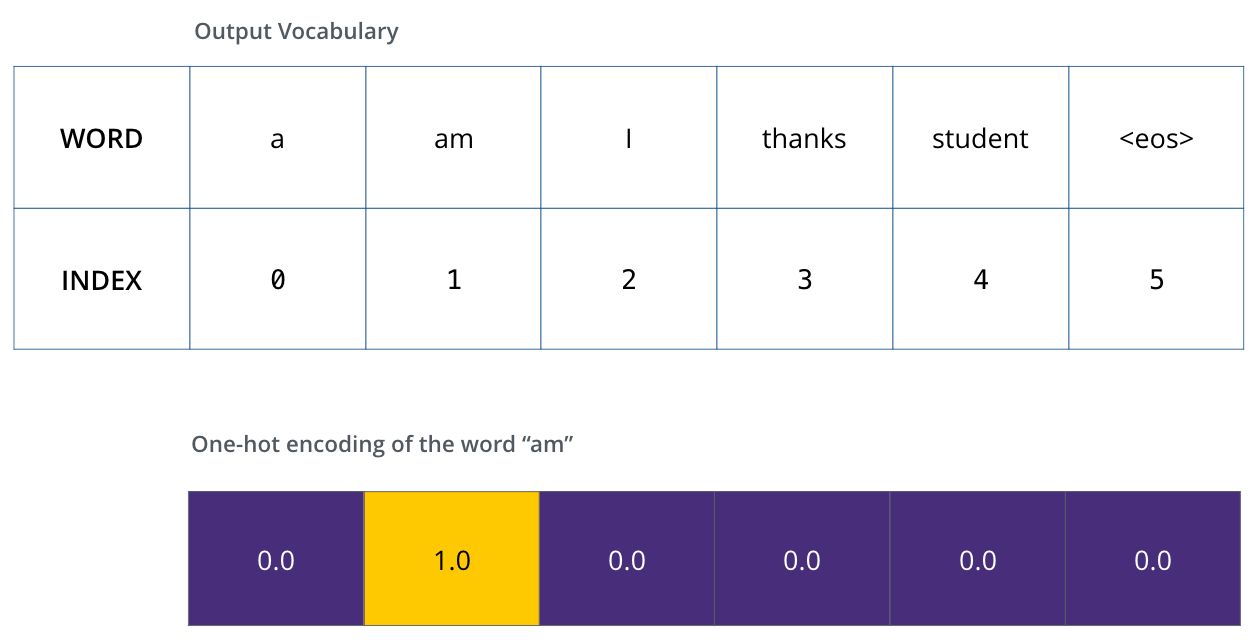
Exemple: codificació ràpida del nostre vocabulari de sortida
Després d’aquest resum, parlem de la funció de pèrdua del model: la mètrica que estem optimitzant durant la fase d’entrenament per conduir a un model entrenat i, amb sort, sorprenentment precís.
La funció de pèrdua
Diguem que estem entrenant el nostre model. Diguem que és el nostre primer pas en la fase d’entrenament, i l’estem entrenant amb un exemple senzill: traduir “merci” en “gràcies”.
Això vol dir que volem que la sortida sigui una distribució de probabilitat que indiqui la paraula “gràcies”. Però com que aquest model encara no està entrenat, és poc probable que això passi encara.
![]()
Com que els paràmetres (pesos) del model s’inicien tots aleatòriament, el model (no entrenat) produeix una distribució de probabilitat amb valors arbitraris per a cada cel·la/paraula. Podem comparar-lo amb la sortida real i, a continuació, ajustar tots els pesos del model mitjançant la retropropagació per apropar la sortida a la sortida desitjada.
Com compares dues distribucions de probabilitat? Simplement restem un de l’altre. Per obtenir més detalls, mireu l’entropia creuada i la divergència de Kullback-Leibler .
Però tingueu en compte que aquest és un exemple excessivament simplificat. De manera més realista, utilitzarem una frase més llarga que una paraula. Per exemple: entrada: “je suis estudiant” i sortida esperada: “sóc un estudiant”. El que això realment significa, és que volem que el nostre model produeixi successivament distribucions de probabilitat on:
- Cada distribució de probabilitat està representada per un vector d’amplada vocab_size (6 en el nostre exemple de joguina, però de manera més realista un nombre com 30.000 o 50.000)
- La primera distribució de probabilitat té la probabilitat més alta a la cel·la associada amb la paraula “i”
- La segona distribució de probabilitat té la probabilitat més alta a la cel·la associada amb la paraula “am”
- I així successivament, fins que la cinquena distribució de sortida indiqui el
<end of sentence>símbol ‘ ‘, que també té associada una cel·la del vocabulari de 10.000 elements.
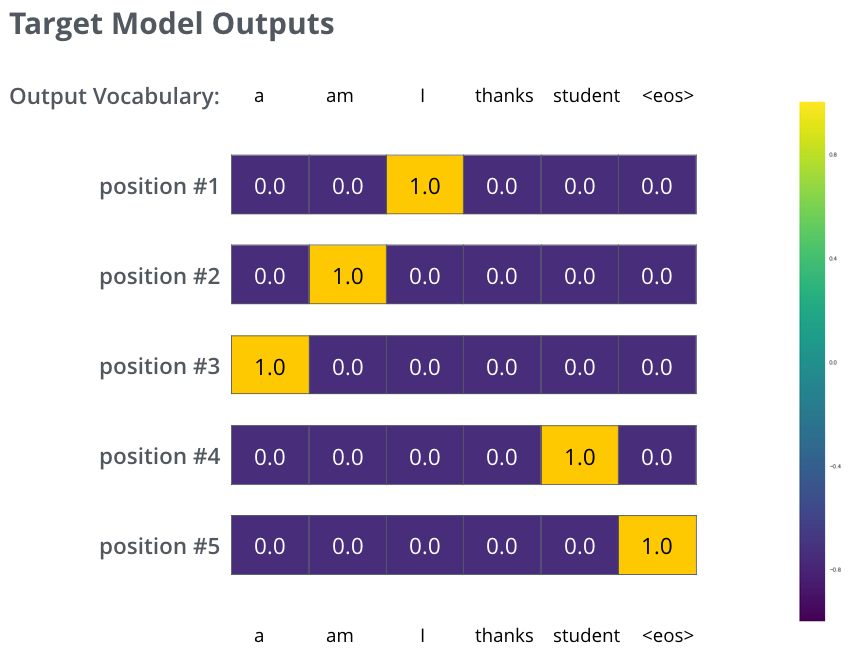
Les distribucions de probabilitat orientades amb les quals entrenarem el nostre model a l’exemple d’entrenament per a una frase de mostra.
Després d’entrenar el model durant prou temps en un conjunt de dades prou gran, esperem que les distribucions de probabilitat produïdes tinguessin aquest aspecte:
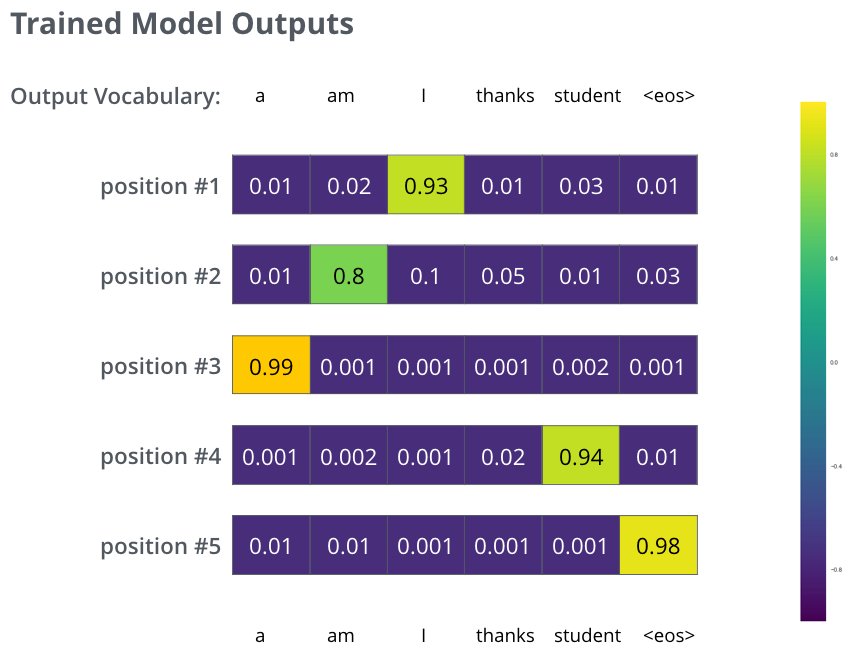
Tant de bo, després de l’entrenament, el model produiria la traducció correcta que esperem. Per descomptat, no és cap indicació real de si aquesta frase formava part del conjunt de dades d’entrenament (vegeu:
validació creuada ). Tingueu en compte que cada posició té una mica de probabilitat, fins i tot si és poc probable que sigui la sortida d’aquest pas de temps; aquesta és una propietat molt útil de softmax que ajuda al procés d’entrenament.
Ara, com que el model produeix les sortides una a la vegada, podem suposar que el model selecciona la paraula amb la probabilitat més alta d’aquesta distribució de probabilitat i llença la resta. Aquesta és una manera de fer-ho (anomenada descodificació cobdiciosa). Una altra manera de fer-ho seria mantenir, per exemple, les dues paraules principals (per exemple, “I” i “a”, per exemple), i al següent pas, executar el model dues vegades: una vegada assumint que la primera posició de sortida era la paraula “I”, i una altra vegada assumint que la primera posició de sortida era la paraula “a”, i es manté la versió que va produir menys error tenint en compte les dues posicions #1 i #2. Repetim això per a les posicions #2 i #3… etc. Aquest mètode s’anomena “cerca de bigues”, on en el nostre exemple, beam_size era dos (és a dir, que en tot moment es conserven dues hipòtesis parcials (traduccions inacabades) a la memòria), i top_beams també és dos (és a dir, retornarem dues traduccions). ). Aquests són tots dos hiperparàmetres amb els quals podeu experimentar.
Avança i transforma’t
Espero que hagis trobat aquest lloc útil per començar a trencar el gel amb els conceptes principals del Transformer. Si voleu aprofundir, us proposo aquests passos següents:
- Llegiu el document Attention Is All You Need , la publicació del bloc de Transformer ( Transformer: A Novel Neural Network Architecture for Language Understanding ) i l’ anunci de Tensor2Tensor .
- Mira la xerrada de Łukasz Kaiser recorrent el model i els seus detalls
- Juga amb el Jupyter Notebook proporcionat com a part del repositori Tensor2Tensor
- Exploreu el repositori Tensor2Tensor .
Treballs de seguiment:
- Convolucions separables en profunditat per a la traducció automàtica neuronal
- Un model per aprendre-los tots
- Autoencoders discrets per a models de seqüència
- Generació de la Viquipèdia resumint seqüències llargues
- Transformador d’imatge
- Consells d’entrenament per al model Transformer
- Autoatenció amb representacions de posició relativa
- Decodificació ràpida en models de seqüència mitjançant variables latents discretes
- Adafactor: taxes d’aprenentatge adaptables amb cost de memòria sublineal
Agraïments
Gràcies a Illia Polosukhin , Jakob Uszkoreit , Llion Jones , Lukasz Kaiser , Niki Parmar i Noam Shazeer per oferir comentaris sobre versions anteriors d’aquesta publicació.
Si us plau, truqueu-me a Twitter per a qualsevol correcció o comentari. Escrit el 27 de juny de 2018

I’ve always been captivated by the wonders of science, particularly the intricate workings of the human mind. With a degree in psychology under my belt, I’ve delved deep into the realms of cognition, behavior, and everything in between. Pouring over academic papers and research studies has become somewhat of a passion of mine – there’s just something exhilarating about uncovering new insights and perspectives.